Overview
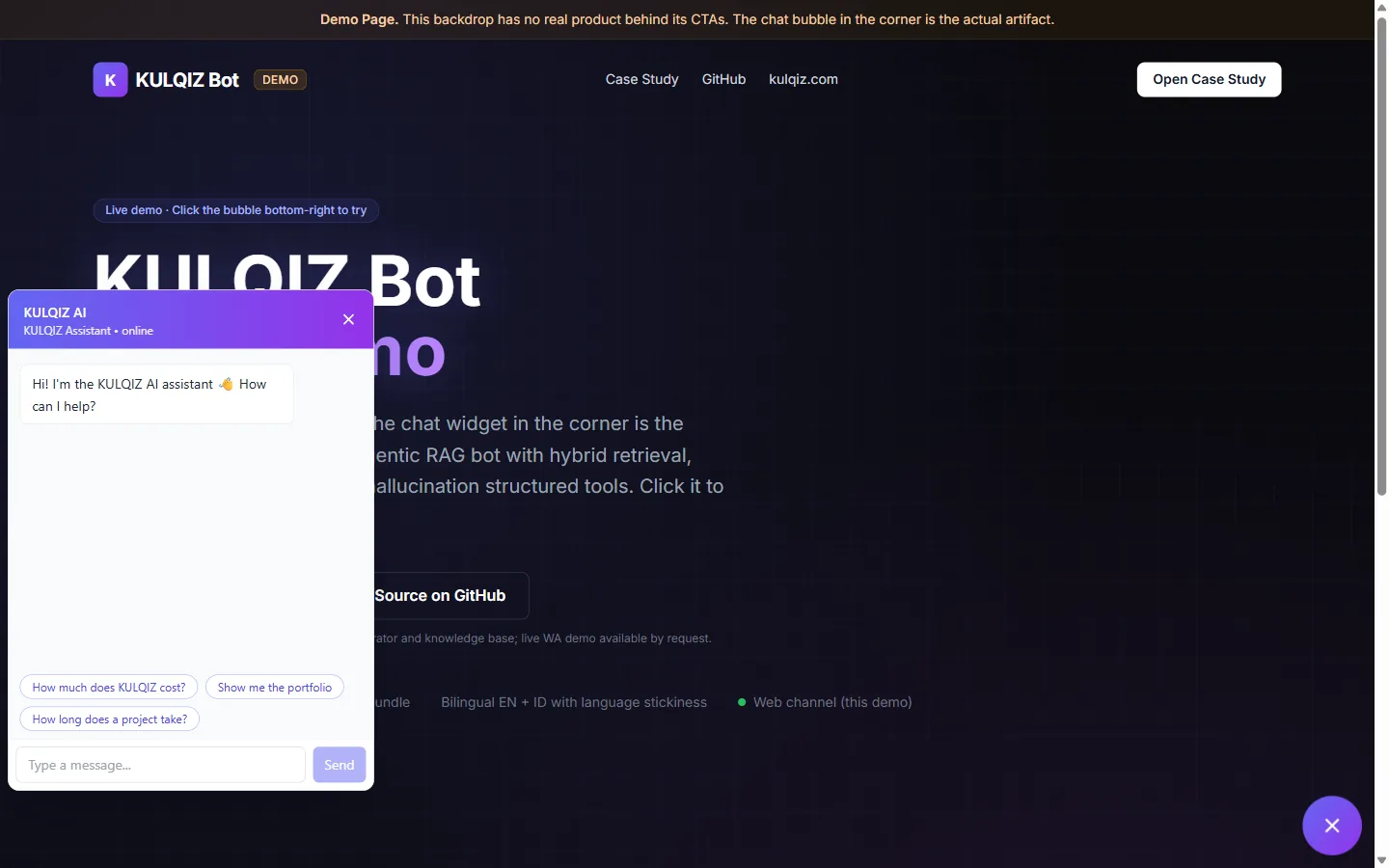
A production-grade customer support agent for small and medium businesses, built from scratch as an end-to-end demonstration of agentic AI engineering. The shipped, live channel is an embeddable web widget that runs on this very site (open the chat bubble in the corner). It answers about 80% of repetitive support questions 24/7 from a knowledge base, captures qualified leads using BANT scoring, and escalates the complex 20% to a human admin. A WhatsApp channel was prototyped on the same orchestrator but is currently deferred; because the core is channel-agnostic, WhatsApp is an adapter away rather than a rewrite.
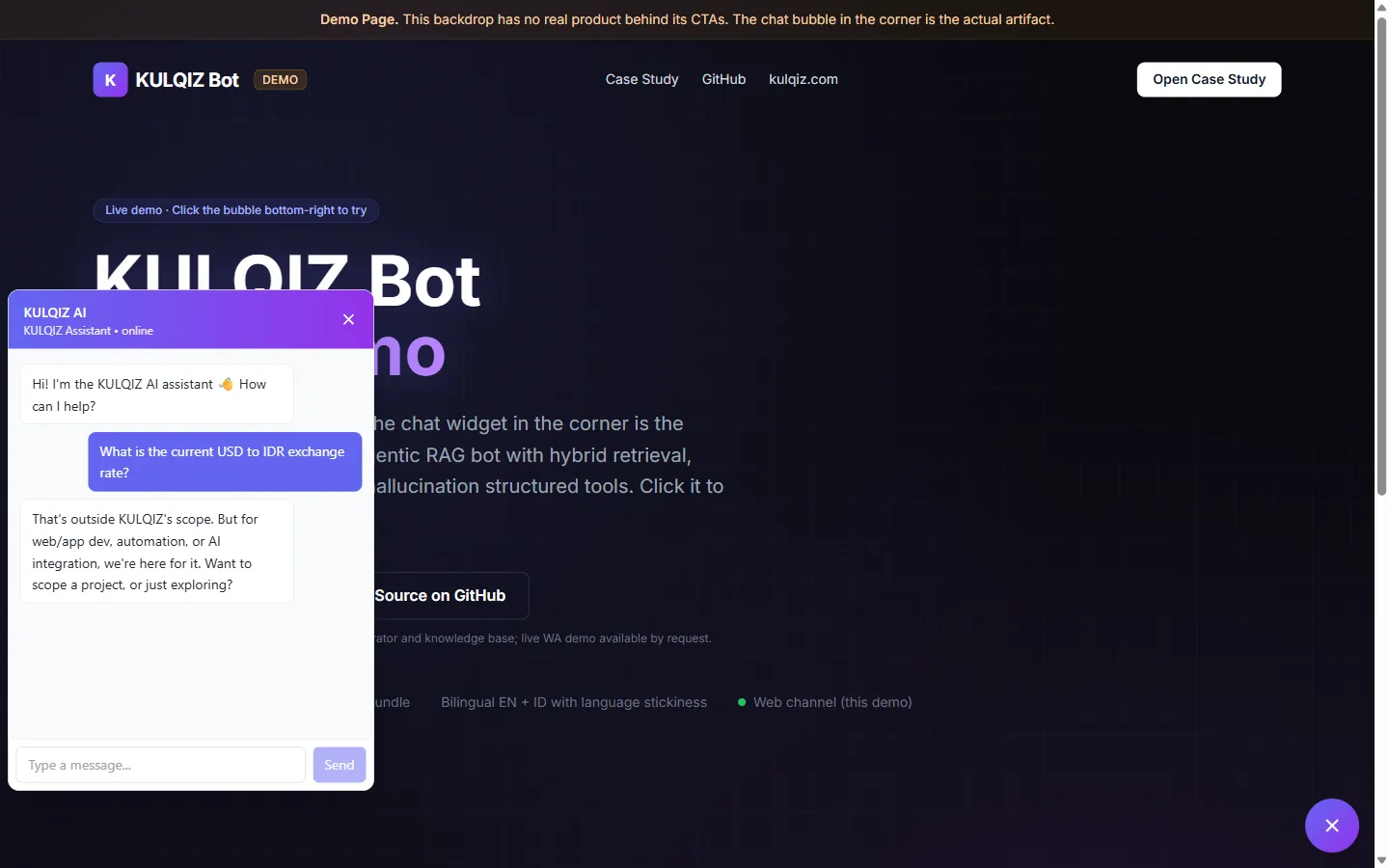
Unlike pure RAG chatbots that retrieve documents for every message, this agent uses an adaptive brain LLM that classifies intent first and skips retrieval roughly 60% of the time. Pricing and portfolio lookups go to deterministic JSON tools, eliminating hallucination on numbers. Out-of-scope queries (currency, weather, code generation) are refused politely instead of confabulating answers.
The stack is intentionally lean: Featherless flat-rate plan for all LLM calls plus a single small VPS gets the whole thing into production. Designed for predictable, low-overhead operation that does not get squeezed by per-seat or per-token vendor pricing.
Challenge
Most SMB chatbot vendors lock customers into proprietary per-seat platforms with limited control over data, prompts, and model selection. A solo Indonesian web studio wanted to offer comparable functionality to local clinics, e-commerce stores, and agencies with full ownership of the stack and the ability to self-host.
The technical requirements were demanding:
- A channel-agnostic core: the same orchestrator and knowledge base serve the embeddable web widget (shipped, live) and a WhatsApp channel (built, deferred)
- Zero hallucination on prices and portfolio items, because giving a wrong rupiah figure to a real customer destroys trust
- Bilingual operation (Indonesian and English) with language stickiness so a courtesy “thanks” doesn’t flip the entire session
- Safety guardrails: rate limiting, prompt injection defense, PII output masking, per-session token budgets
- Production observability with traces of every conversation turn
- Lean stack design so a solo operator can support and resell without dependency on vendor pricing changes
Solution
Five-layer agentic architecture
The system was designed as five focused sub-projects that build on each other, each shipped with its own spec, plan, and test suite:
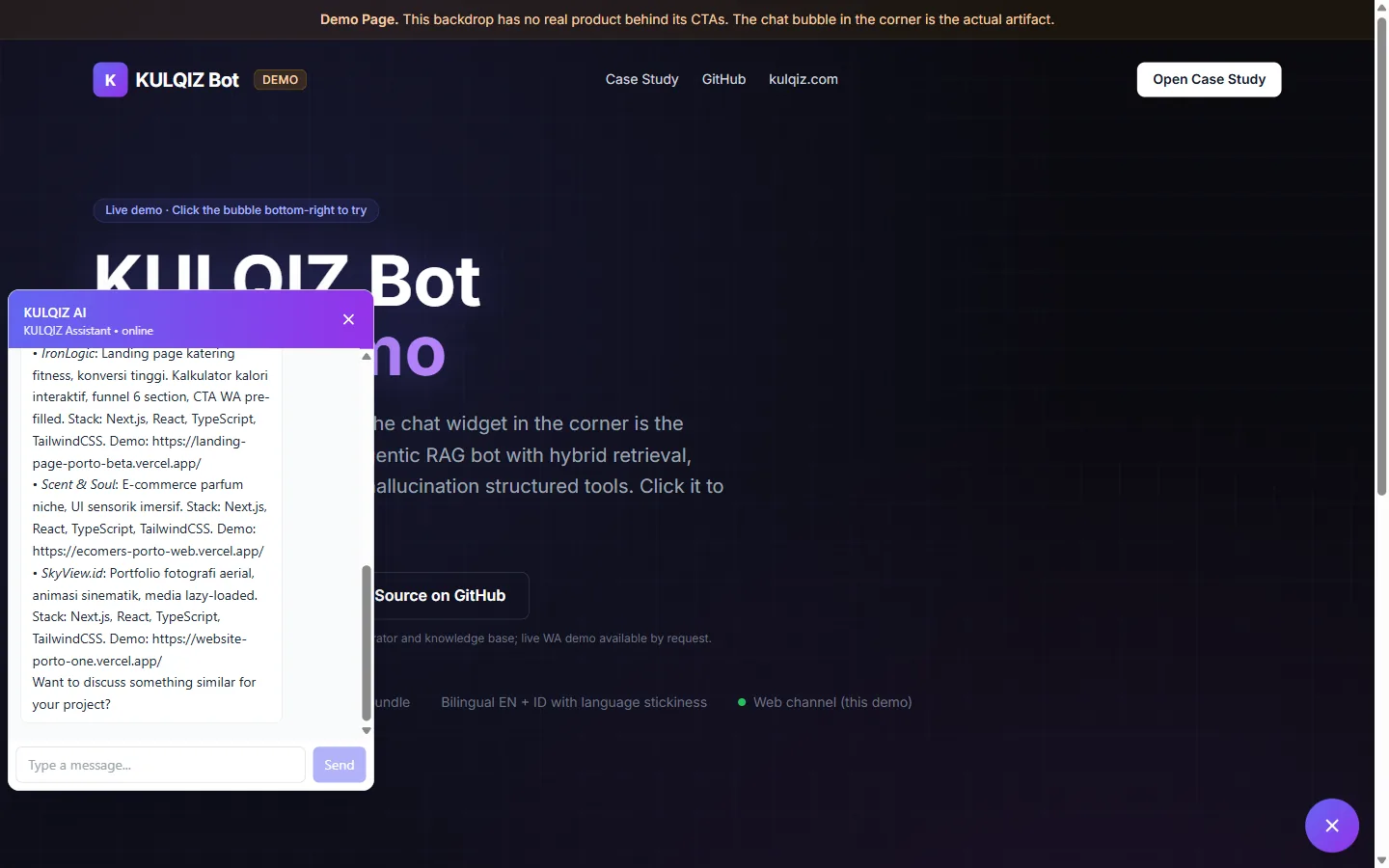
- Sub-project A. Retrieval Quality. Hybrid retrieval combining BM25 keyword search, dense vector search (Qwen3-Embedding-4B), Reciprocal Rank Fusion at k=60, then an LLM-as-reranker pass with Qwen3-8B. About 81% accuracy on complex queries, well above pure dense retrieval baselines.
- Sub-project B. Conversation Brain. A single LLM call decides intent (factual / lead / handoff / refuse), routes to the right handler (RAG / tool / refusal / escalation), rewrites the query with coreference resolution, and extracts BANT slots (project type, timeline, budget, contact). Skips retrieval on 60%+ of messages.
- Sub-project C. Safety Layer. Four guards above the orchestrator: sliding-window rate limiter (20 per 5 minutes, 200 per day per phone), regex injection guard with 12 EN/ID jailbreak patterns, PII output masking for emails and phones and credit cards, and a per-session 50K token budget that triggers auto-handoff before runaway conversations drain credits.
- Sub-project D. Web Widget Channel. Vite + Preact floating bubble that embeds on any site via a single
<script>tag. Server-Sent Events streaming, 48 KB gzipped bundle (single file, CSS injected by JS), localStorage UUID sessions. Reuses the same orchestrator as WhatsApp via a thin channel adapter. - Sub-project E. Production Deployment. Docker Compose with 4 services (app + Chroma + Redis + Caddy), L1 embedding cache in SQLite, L2 response cache in Redis with PII-safe write guards, Langfuse Cloud tracing for every conversation turn, Promptfoo CI eval gate on every PR, systemd timer for nightly Puppeteer restart, Cloudflare WAF in front.
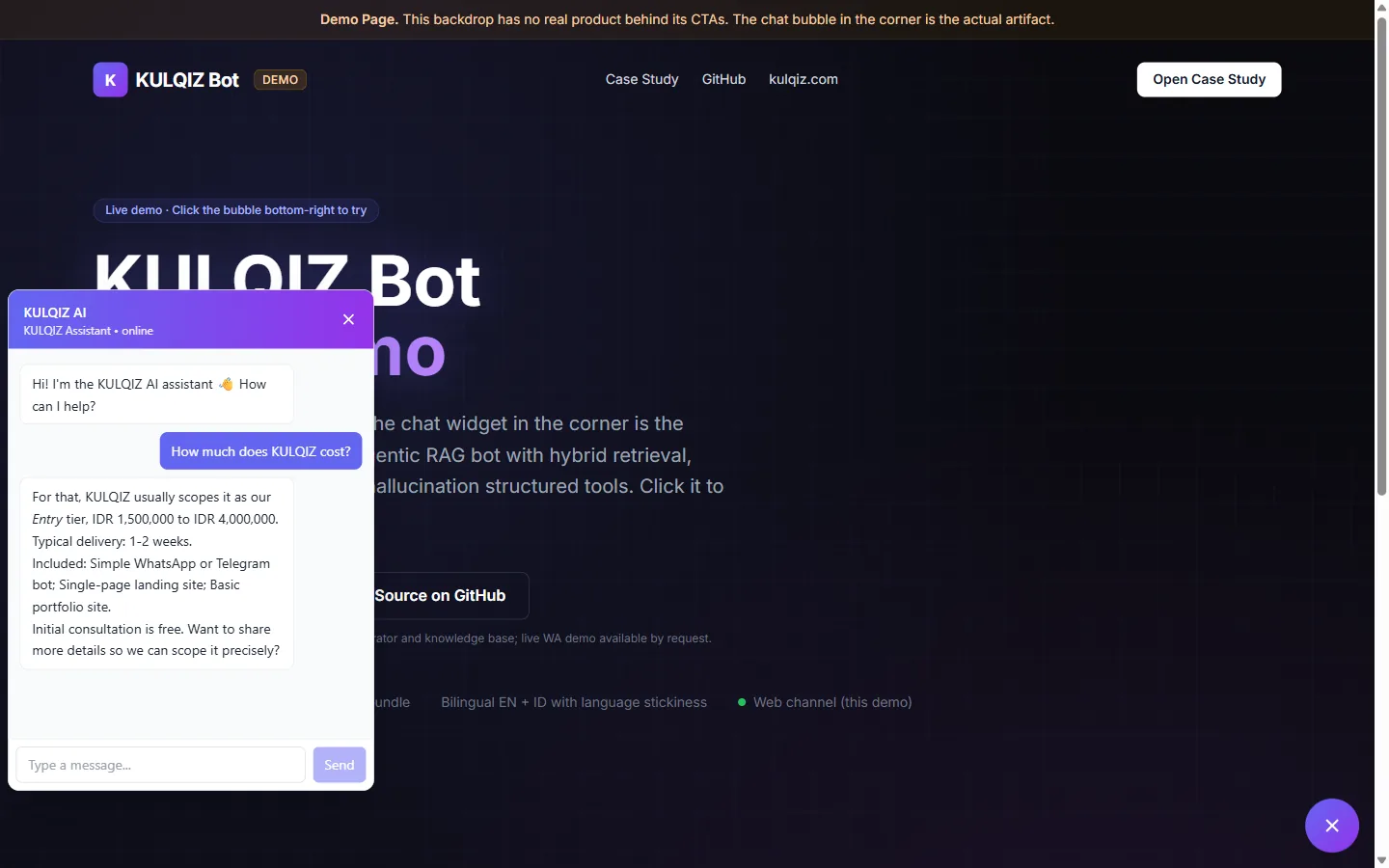
Zero-hallucination structured tools
Pricing and portfolio data are stored as JSON files, not embedded in the vector database. When the brain detects a pricing question, it calls get_pricing(project_type) which reads the file and formats a reply. The LLM never sees the raw price numbers in its context, so it cannot invent or misquote them. This is a deliberate departure from “embed everything” RAG tutorials and has been the single biggest reliability win in production testing.
Language stickiness with smart switching
After a regression where the bot flipped to English mid-conversation because the user wrote “thanks”, the brain prompt was rewritten with a session-sticky rule: default to the language the assistant used in its most recent reply, only override when the latest message has 3+ content words in the other language (excluding courtesy borrowed words). Six explicit examples in the prompt cover edge cases like Jakarta-style code-switching.
Anti-hallucination relevance gate
When retrieval scores are low and the user query is substantial (over 25 characters), the bot returns a polite “I haven’t found that in the knowledge base, could you share more context?” reply instead of letting the LLM generate from low-relevance chunks. Short conversational queries like greetings bypass the gate so the LLM can respond naturally. This caught a real bug where a question like “1 USD” was triggering an invented exchange rate; the gate combined with brain refusal patterns now blocks the entire class of realtime-data hallucinations.
Lean infrastructure
Everything runs on a flat-rate Featherless plan for all LLM calls (Qwen3-8B brain, Qwen3-8B reranker, Qwen2.5-7B generator, Qwen3-Embedding-4B) plus a single small VPS. Supporting services (ChromaDB, Redis, Caddy, Cloudflare WAF, Langfuse Cloud, Promptfoo CI on GitHub Actions) run on free or open-source tiers. The L1 embedding cache eliminates LLM calls on repeat queries; the L2 response cache (when Redis is wired in) caches FAQ-style responses for 24 hours with automatic PII bypass.
Results
- Test coverage → 150 unit tests passing (146 backend node:test + 4 widget vitest), zero TypeScript errors at strict mode, with dependency-injection seams in the orchestrator for clean test isolation.
- Widget bundle → 48 KB gzipped single file. One
<script>tag embeds the entire chat experience including styles. Down from 211 KB after Preact swap and CSS-inject-by-JS plugin. - Channel-agnostic core → the web widget is the live channel; the WhatsApp adapter targets the exact same orchestrator pipeline (built, deployment deferred). Adding another channel (Telegram, voice) is a thin adapter, not a rewrite.
- Stack ownership → Full code ownership and self-host capability versus per-seat SaaS chatbots (Intercom Fin, Botpress, ChatBot.com) that lock customers into proprietary platforms. Avoids vendor pricing surprises and gives full control over data, prompts, and model selection.
- Bugs caught via end-to-end testing → A Playwright session uncovered a SSE race condition where
req.on("close")was firing prematurely after Express body parsing, causing every widget request to hang with zero bytes. That single bug would have shipped to production silently if testing had stopped at unit level. Lesson logged: always run real browser flows before declaring features complete.
Architecture diagram
The agent routes each inbound message through this decision pipeline before any retrieval happens:
incoming message (live web widget · WhatsApp adapter ready)
↓
[Safety: rate limit → injection guard → token budget]
↓
[Brain LLM 1-shot: intent + tool + query rewrite + BANT slots + language]
↓
├─ refuse → canned refusal (no retrieval, no LLM gen)
├─ handoff → escalate to a human admin (push)
├─ tool=pricing → read pricing.json (no RAG, no hallucination)
├─ tool=portfolio → read portfolio.json (no RAG)
└─ factual + tool=null → RAG path
↓
[L2 response cache check]
hit → return cached reply
miss → embed query (L1 cache) → hybrid retrieve →
LLM rerank → relevance gate → generate →
PII mask → cache write (if PII-free)
↓
[Lead capture: BANT scoring, hot lead (≥70) → admin push]
[Session memory: 7-day sliding window, last 6 turns to brain]
[Reply: stripDashes filter → SSE chunk or WA send]Tech Stack rationale
- Featherless over OpenAI: flat-rate billing instead of per-token pricing avoids cost spikes during traffic bursts, Qwen3 family is strongest for Indonesian + multilingual support per MMTEB benchmarks, no-logging policy aligns with data minimization goals.
- ChromaDB over Pinecone: open source, native hybrid BM25+dense from v1.x onward, runs in the same Docker network as the app, swap to Qdrant later via the abstract
VectorStoreinterface if scale demands. - Preact over React: 40 KB bundle size win, drop-in compat alias in Vite, same component code. Critical for widget embed where every KB matters.
- whatsapp-web.js over WhatsApp Cloud API (for the optional, currently-deferred WhatsApp channel): zero per-message cost for a pilot, drop-in replaceable with WAHA self-hosted or the Cloud API when that channel is activated.
- Caddy over nginx: auto-HTTPS via Let’s Encrypt with zero config, smaller memory footprint, Caddyfile is half the lines of an equivalent nginx config.